Sanırım en iyisi, bugünkü merakımı gidermek için AlphaZero ile Stockish arasındaki 1. oyunda bir örnek hareketle ikinci noktanızı hazırlarsam.
1 dk / hamle zaman sınırı (Bu dezavantajı Stockish nasıl olurdu?)
Stockfish'in performansı hem zaman sınırına hem de donanım konfigürasyonuna bağlıdır, bu yüzden birinin CPU ipliklerini ne zaman iki katına çıkardığını düşünün, o zaman çözümü bulmak için ilk konfigürasyonda olduğundan daha az zaman gerekir (mutlaka yarısı değil).
Chess.com'da yayınlanan ilk raporda birileri bilgisayarında aynı sonuçları elde edemediği için Stockish'in en iyi şekilde oynamadığını iddia etti. Aşağıdaki pozisyonda olduğunu söyledi (oyun 1 - hareket 11) Stockish hiçbir anlam ifade etmedi Kg1-h1 (kralı taşındı) oynadı. Öte yandan, bilgisayarındaki stockfish, Be3 (karanlık kare piskoposunu hareket ettir) gibi daha gelişmekte olan bir hareket gösterdi, pozisyonuna bakalım:
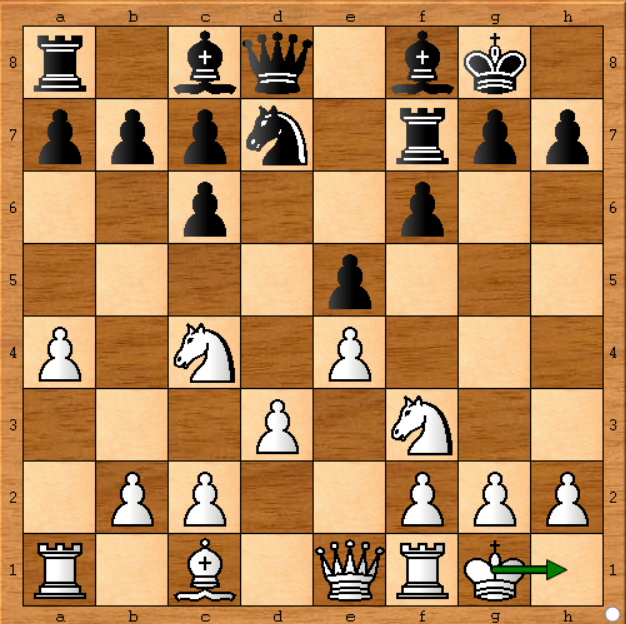
Evet, pasif bir hamleydi ve sanırım Stockish daha gelişmekte olan bir hamle oynamış olmalıydı. Ama yanılıyordu. Niye ya? Çünkü 15 saniye Stockish koştu ve bir saat boyunca koşmuş olsaydı, Kg1-h1'i bu pozisyondaki en iyi hareket olarak kazanmış olacaktı. Stockish, tüm olası hareketleri daha derinlemesine analiz ettiğinde kararını değiştiriyor. İşte cevabımda ilk söylediklerim :
En son balık stokunu pozisyona koştum (11 numaralı hamleyde):
- İlk başta, b4, motor yaklaşık bir dakika çalıştığında en uygun hareket olarak verir. Bundan sonra, Be3'ün daha iyi olduğuna karar verir.
Ancak 1.400k düğüm / sn'de çalışan donanımım üzerinde 5 dakika sonra en uygun hareket olarak Kh1 ile çalışmaya karar verecek.
Makalede, stok balıklarının saniyede 70.000k pozisyonu hesapladığı ve hamle başına 1 dakika çalıştığı söyleniyor, donanımımın yaklaşık 50 katı, bu yüzden benimki 50 dakika boyunca koşmaya izin vereceğim ... Kg1-h1 hala Stockish için seçim.
Zaman sınırı anahtarıdır
Yukarıdaki durumda, Stockish, kararın aynı olacağı için iki kez koştuğu için bir önemi yoktu, ama bir sonraki harekette kesinlikle :
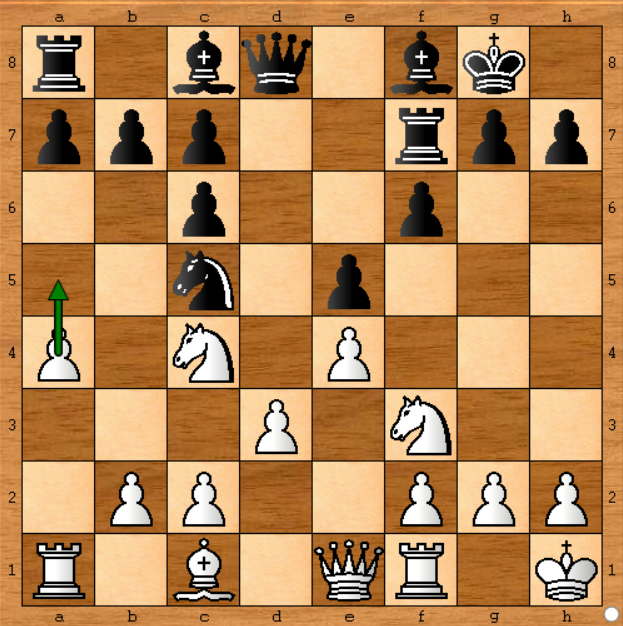
Bu pozisyonda Stockish piyonu sol tarafa taşımayı tercih etti ( a4-a5 ). Diyelim ki, Stockish motorunu saniyede 1.400k düğüm hızında çalıştıran bir bilgisayarım var, bu gerçek oyunda Stockish'ten yaklaşık 50 kat daha düşük ( Bu yazıda 70.000kn / s). Böylece her hamlede 50 dakika boyunca çalıştırırsam oyunu simüle edebilirim. Tamam.
Yukarıdaki pozisyonda Stockish analizini yaptım ve aşağıdaki sonuçları aldım:
- Stockish bazı hareketler öne sürmeye başladı, ancak bilgisayarımdaki 6 dakika sonra ( gerçek oyunda Stockish'in 7.2 saniyesine denk geldi ) oyunun ilerleyişinde a4-a5'i tercih etti .
Bu iyi, ancak 1 dakikalık izin verilen oyunda Stockish'in hesaplarına ulaşmak için 50 dakika boyunca çalışmasını sağladım:
Üzücü gerçek şu ki, Stockish'in zaman kaybettiği için tüm oyunlarını kaybettiğine inanıyor. Stockish zaman geçtikçe oyunda derinlemesine bir araştırma ve değerlendirme alıyor ve oyunda sığ derinliklerde birçok hareketi düşünen bir açılış kitabı kullanmasına izin verilmiyordu. Asıl oyunda a4-a5'in oynandığını ve bu sayede (saniyede 70 milyon pozisyonu değerlendirebileceğini varsayarak) oyundaki Stockish'in hareket halindeyken 21.6 saniyeden fazla zaman harcamamış olduğunu unutmayın. Aksi takdirde, kararını gerçek oyunda bu üç hamle olarak değiştirmiş olacaktı. Bunların nedeni hala benim için net değil çünkü Stockish'im de daha az bellek tüketiyordu ( orijinal belgede belirtilen 1 GB'ye kıyasla yaklaşık 130 MB RAM , hepsinin karma tablolara gittiğini düşünerek).
Sonuç
Stockish'in belirttiği donanım, belirttiğim gibi, analiz ettiğim harekete dayanarak benimkinden (Update: tek bir çekirdekte) 18 kat daha hızlıydı. AlphaZero'nun 4 saat içinde ağlarını eğitmek için bu tür donanımları gerçekten kullanabileceğinden emin değilim, sadece satranç gibi bir oyun için çok düşük olduğunu varsayabilirim. Ayrıca, AlphaZero bu saatleri öğrenme için harcayarak açıklıklar inşa etmeyi de (ve makalenin belirttiği gibi, belirli açıklıklar tercihleri) harcadı. Öte yandan, Stockish açılışlarda sakatlandı ve her seferinde 60 saniye boyunca saniyede 70 milyon pozisyonu değerlendirmedi.
Son bir not olarak, söylediğim her şey varsayımlarıma dayanıyordu. Tabii ki, AlphaZero ve oyunların sonucu benim için çok ilginçti. Ancak, Stockish oyununun tıpkı benim bilgisayarımda edindiğim gibi olduğu bir oyun görmeyi çok isterdim. Yani, daha fazla zaman ve bir açılış kitabı. Her analizde Stockish analizinin çıktılarını elde etmek de kolaydır ve performansının ne kadar iyi olduğunu göstermek için yayınlamasını diliyorum.