Bir alan adını doğrulamam gerekiyor:
google.com
stackoverflow.com
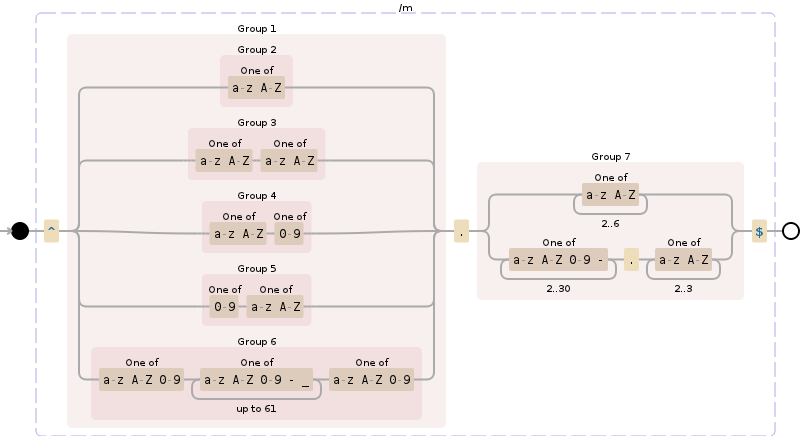
Yani en ham haliyle bir alan adı - www gibi bir alt alan adı bile değil.
- Karakterler sadece az | AZ | 0-9 ve nokta (.) Ve kısa çizgi (-)
- Alan adı kısmı tire (-) ile başlamamalı veya bitmemelidir (örneğin -google-.com)
- Alan adı kısmı 1 ile 63 karakter arasında olmalıdır
Uzantı (TLD) şimdilik 1 numaralı kuralın altındaki herhangi bir şey olabilir, onları daha sonra bir listeye göre doğrulayabilirim, 1 veya daha fazla karakter olsa da
Düzenleme: TLD görünüşte olduğu gibi 2-6 karakterdir
Hayır. 4 revize edildi: TLD, .co.uk gibi şeyleri içermesi gerektiği için aslında "alt alan adı" olarak etiketlenmelidir - Mümkün olan tek doğrulamanın (bir listeyle karşılaştırmanın dışında) 'ilk noktadan sonra bir tane olmalı veya 1. kural altında daha fazla karakter
Çok teşekkürler, inanın denedim!
1
Hiç yardımcı olmayabilir. Google.co.uk ve bazı Japonca alan adları söz konusu olduğunda, bunun için regex kullanmadan önce iki kez düşünmeniz gerekeceğinden eminim. Benim kişisel düşüncem, regex'in bir alanı gerçek hayattaki bir alana doğrulamak için yeterli olmadığıdır. Bilginize, işte tlds ve ülke kodu ikinci seviye alan adları listesinin neredeyse eksiksiz bir listesi: static.ayesh.me/misc/SO/tlds.txt
—
Ayesh K
Ana bilgisayar adı doğrulaması ile ilgili soruya verdiğim yanıtı görün .
—
SAM
Çoğu zaman unutulur: Tam nitelikli alan adları için, tld'den sonra bir nokta ile eşleşmelisiniz.
—
schmijos
4 yıl oldu, şimdi sayı
—
89.000'e çıktı
Bu cevaplardan bazıları oldukça iyi, ancak bu diğer soruya bakmaya değer başka bir iyi cevap daha var.
—
craftworkgames