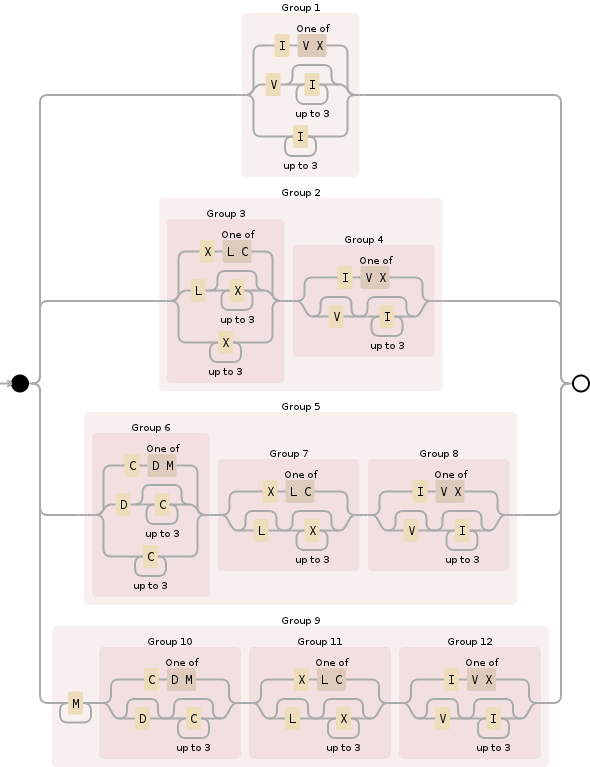
Bunun için aşağıdaki normal ifadeyi kullanabilirsiniz:
^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
Aşağı Breaking, M{0,4}binlerce bölümünü belirtir ve temelde arasında onu alıkoyar 0ve 4000. Nispeten basit:
0: <empty> matched by M{0}
1000: M matched by M{1}
2000: MM matched by M{2}
3000: MMM matched by M{3}
4000: MMMM matched by M{4}
Elbette, daha büyük sayılara izin vermek istiyorsanız, herhangi bir sayıya (sıfır dahil) binlerce M*izin vermek gibi bir şey kullanabilirsiniz .
Sonraki (CM|CD|D?C{0,3}), biraz daha karmaşık, bu yüzlerce bölüm içindir ve tüm olasılıkları kapsar:
0: <empty> matched by D?C{0} (with D not there)
100: C matched by D?C{1} (with D not there)
200: CC matched by D?C{2} (with D not there)
300: CCC matched by D?C{3} (with D not there)
400: CD matched by CD
500: D matched by D?C{0} (with D there)
600: DC matched by D?C{1} (with D there)
700: DCC matched by D?C{2} (with D there)
800: DCCC matched by D?C{3} (with D there)
900: CM matched by CM
Üçüncüsü, (XC|XL|L?X{0,3})onlarca yer için önceki bölümle aynı kuralları izler:
0: <empty> matched by L?X{0} (with L not there)
10: X matched by L?X{1} (with L not there)
20: XX matched by L?X{2} (with L not there)
30: XXX matched by L?X{3} (with L not there)
40: XL matched by XL
50: L matched by L?X{0} (with L there)
60: LX matched by L?X{1} (with L there)
70: LXX matched by L?X{2} (with L there)
80: LXXX matched by L?X{3} (with L there)
90: XC matched by XC
Ve son olarak, (IX|IV|V?I{0,3})taşıma, birimler bölümdür 0içinden 9ve önceki iki bölümde (ne olduklarını anlamaya kez Romen rakamları, onların görünüşteki garabeti rağmen bazı mantıksal kuralları takip edin) da benzer:
0: <empty> matched by V?I{0} (with V not there)
1: I matched by V?I{1} (with V not there)
2: II matched by V?I{2} (with V not there)
3: III matched by V?I{3} (with V not there)
4: IV matched by IV
5: V matched by V?I{0} (with V there)
6: VI matched by V?I{1} (with V there)
7: VII matched by V?I{2} (with V there)
8: VIII matched by V?I{3} (with V there)
9: IX matched by IX
Bu normal ifadenin de boş bir dizeyle eşleşeceğini unutmayın. Bunu istemiyorsanız (ve regex motorunuz yeterince modernse), olumlu bakış ve ileriye bakabilirsiniz:
(?<=^)M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})(?=$)
(diğer alternatif, uzunluğun önceden sıfır olmadığını kontrol etmektir).