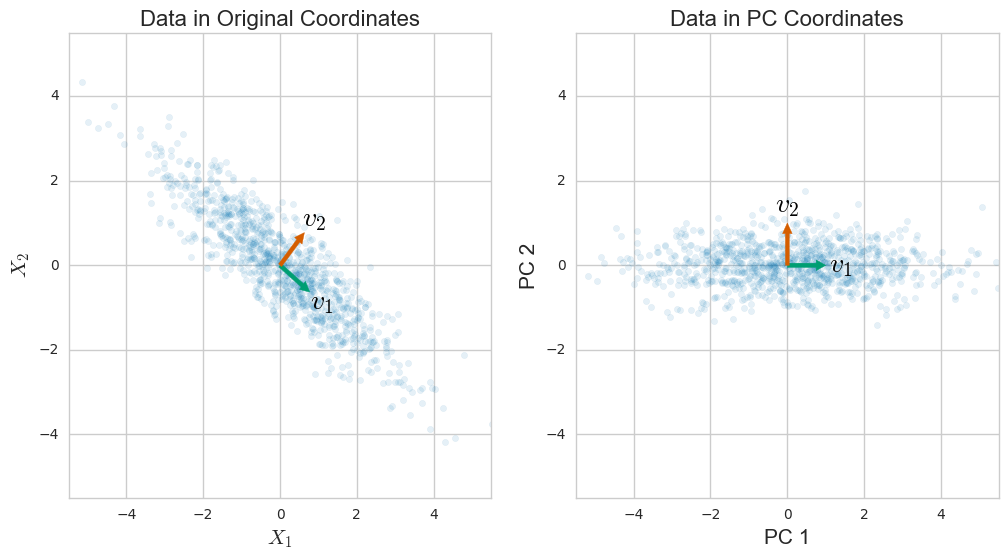
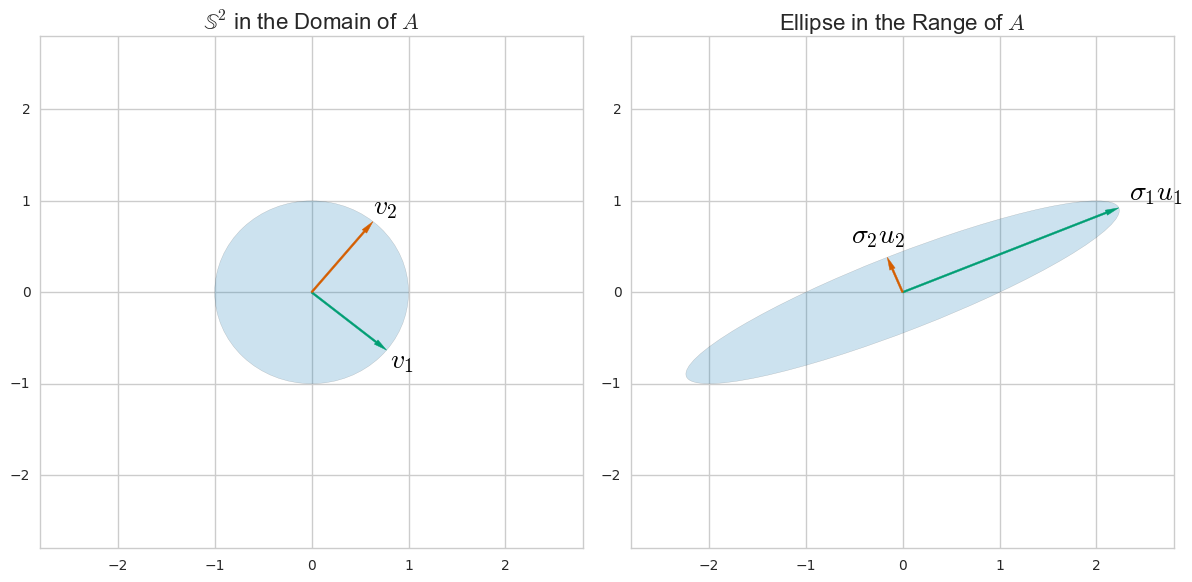
Temel bileşen analizi (PCA) genellikle kovaryans matrisinin bir öz-ayrışmasıyla açıklanır. Bununla birlikte, veri matrisinin tekil değer ayrıştırması (SVD) yoluyla da gerçekleştirilebilir . O nasıl çalışır? Bu iki yaklaşım arasındaki bağlantı nedir? SVD ile PCA arasındaki ilişki nedir?
Başka bir deyişle, boyutsallık azaltma gerçekleştirmek için veri matrisinin SVD'si nasıl kullanılır?
8
Bu SSS tarzı soruyu kendi cevabımla birlikte yazdım, çünkü sıkça çeşitli şekillerde soruluyor, ancak kanonik bir konu yok ve bu yüzden kopyaları kapatmak zor. Lütfen bu beraberindeki meta dizisine meta yorumlar yazın .
—
amip
Onun daha da bağlantıları ile mükemmel ve ayrıntılı Amoeba'nın cevap ek olarak ben kontrol etmek önerebilir bu PCA yan yana diğer bazı SVD tabanlı teknikler tasavvur edilmektedir. Buradaki tartışma, amiplerin neredeyse aynısı olan amip ile aynı olan cebirini, PCA'yı tarif ederken, [veya ] ' in svd ayrışmasıyla ilgili ufak bir farkla hemen hemen aynıdır. yerine - kovaryans matrisinin eigende bir araya getirilmesiyle yapılan PCA ile ilgili olduğu için kullanışlıdır.
—
ttnphns,
PCA, SVD'nin özel bir halidir. PCA'nın normalize edilmiş verilere, ideal olarak aynı üniteye ihtiyacı var. Matris PCA'da nxn'dir.
—
Orvar Korvar
@OrvarKorvar: Hangi nxn matrisinden bahsediyorsun?
—
Cbhihe