Bu soru, bir lojistik modelin yeterince iyi olup olmadığına nasıl karar verileceğime dair gerçek karışıklığımdan kaynaklanıyor. Bağımlı bir değişken olarak oluşturulduktan iki yıl sonra bireysel projenin durumunu kullanan modellerim var. Sonuç başarılı (1) ya da değil (0). Çiftlerin oluşumu sırasında ölçülen bağımsız değişkenlerim var. Amacım, varsaydığım bir değişkenin çiftlerin başarısını etkileyip etkilemeyeceğini test etmek ve diğer potansiyel etkileri kontrol ederek bu başarıyı etkileyip etkilemediğini test etmektir. Modellerde, ilgi değişkeni önemlidir.
Modeller, 'deki glm()fonksiyon kullanılarak hesaplandı R. Modellerin kalitesini değerlendirmek için, bir kaç şey yaptık: glm()size verir residual deviance, AICve BICvarsayılan olarak. Ayrıca, modelin hata oranını hesapladım ve binned kalıntıları çizdim.
- Komple model, tahmin ettiğim (ve tam modele yerleştirilmiş) diğer modellerden daha küçük bir kalıntı sapmaya, AIC ve BIC'ye sahip, bu da bu modelin diğerlerinden "daha iyi" olduğunu düşünmemi sağlıyor.
- Modelin hata oranı oldukça düşük, IMHO ( Gelman ve Hill'de olduğu gibi, 2007, s.99 ):
error.rate <- mean((predicted>0.5 & y==0) | (predicted<0.5 & y==1)yaklaşık% 20.
Çok uzak çok iyi. Ancak, (artık Gelman ve Hill'in tavsiyesini takiben) binned kalıntıyı çizdiğimde, kutuların büyük bir kısmı% 95 CI'nın dışında kalıyor:
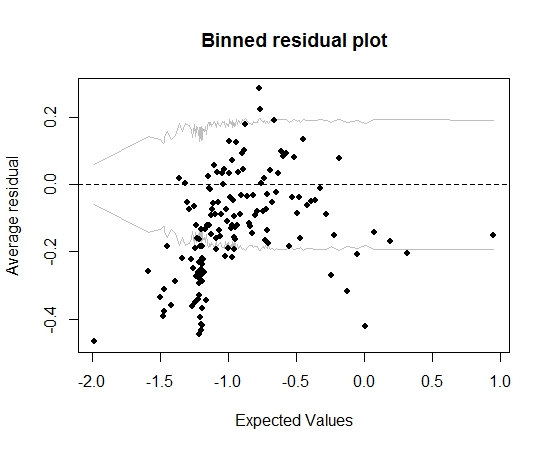
Bu konu beni model hakkında tamamen yanlış bir şey olduğunu düşündürüyor. Bu beni modeli atmaya itmeli mi? Modelin kusurlu olduğunu kabul etmeli miyim, ama onu koruyup ilgilenilen değişkenin etkisini yorumlamalı mıyım? Binned rezidüler arsa gerçekten iyileştirmeden, değişkenleri sırayla ve bazı dönüşümler ile oynadım.
Düzenle:
- Şu anda, modelin bir düzine tahmincisi ve 5 etkileşim etkisi vardır.
- Çiftler, hepsinin kısa bir süre içinde oluşması (ancak sıkıca konuşmama, hepsi aynı anda) anlamında "nispeten" birbirlerinden bağımsızdır ve çok sayıda proje (13k) ve çok sayıda birey (19k) vardır. ), bu nedenle projelerin adil bir kısmına sadece bir kişi katılır (yaklaşık 20000 çift vardır).