Bu soruyu aylardır soruyorum. Görünüşe göre softmax'ı bir çıkış fonksiyonu olarak akıllıca tahmin ettik ve sonra softmax'a girişi log olasılıkları olarak yorumladık. Söylediğiniz gibi, neden tüm çıktıları toplamlarına bölerek normalleştirmeyesiniz? Cevabı Goodfellow, Bengio ve Courville (2016) tarafından 6.2.2'deki Derin Öğrenme kitabında buldum .
Son gizli katmanımızın bize etkinleştirme olarak z verdiğini varsayalım. Sonra softmax şöyle tanımlanır:

Çok Kısa Açıklama
Softmax fonksiyonundaki exp kabaca çapraz entropi kaybındaki logu iptal eder ve kaybın z_i'de kabaca doğrusal olmasına neden olur. Bu, model yanlış olduğunda kabaca sabit bir eğime yol açar ve hızlı bir şekilde kendini düzeltmesine izin verir. Böylece, yanlış doymuş bir softmax kaybolan bir eğime neden olmaz.
Kısa Açıklama
Bir sinir ağını eğitmek için en popüler yöntem Maksimum Olabilirlik Tahmini'dir. Teta parametrelerini egzersiz verilerinin (m büyüklüğünde) olasılığını en üst düzeye çıkaracak şekilde tahmin ediyoruz. Tüm eğitim veri kümesinin olasılığı, her örneğin olasılığının bir ürünü olduğundan, veri kümesinin günlük olasılığını ve dolayısıyla k ile endekslenen her örneğin günlük olasılığı olasılığını en üst düzeye çıkarmak daha kolaydır :
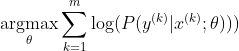
Şimdi, sadece burada z ile verilen softmax'a odaklanıyoruz, böylece değiştirebiliriz
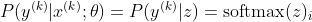
ben kth örneğinin doğru sınıfı olmak. Şimdi, görüyoruz ki softmax'ın logaritmasını aldığımızda, numunenin log olasılığını hesaplamak için:
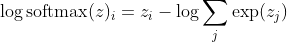
, z'deki büyük farklılıklar için kabaca yaklaşık
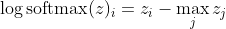
İlk olarak, burada z_i doğrusal bileşenini görüyoruz. İkinci olarak, max (z) 'nin davranışını iki durum için inceleyebiliriz:
- Model doğruysa, max (z) z_i olacaktır. Bu nedenle, log olabilirliği, z_i ve z'deki diğer girdiler arasında artan bir farkla sıfırı (yani 1 olasılığı) asimptote eder.
- Model yanlışsa, max (z) başka bir z_j> z_i olacaktır. Bu nedenle, z_i eklenmesi -z_j'yi tamamen iptal etmez ve günlük olasılığı kabacadır (z_i - z_j). Bu, modele günlük olasılığını artırmak için ne yapılacağını açıkça gösterir: z_i değerini artırın ve z_j değerini azaltın.
Genel log olasılığına, modelin yanlış olduğu örneklerin hakim olacağını görüyoruz. Ayrıca, model gerçekten yanlış olsa bile, doymuş bir softmax'a neden olur, kayıp fonksiyonu doymaz. Yaklaşık olarak z_j cinsinden doğrusaldır, yani kabaca sabit bir gradyanımız vardır. Bu, modelin kendini hızlı bir şekilde düzeltmesini sağlar. Örneğin, Ortalama Kare Hatası için durumun böyle olmadığını unutmayın.
Uzun Açıklama
Softmax hala sizin için keyfi bir seçim gibi görünüyorsa, sigmoidi lojistik regresyonda kullanma gerekçesine bir göz atabilirsiniz:
Neden başka bir şey yerine sigmoid işlevi?
Softmax, benzer şekilde gerekçelendirilen çok sınıflı problemler için sigmoidin genelleştirilmesidir.



